
Open Data Blend July 2021 Update


16th July 2021
By Open Data Blend Team
English Prescribing Data for May 2021 Now Available
We've updated the Prescribing dataset with the latest NHS English Prescribing Data updates for May 2021. You can download the data from the Open Data Blend Datasets Prescribing page, or analyse it directly in supported BI tools through the Open Data Blend Analytics service.
More Free Monthly Downloads
The previous limit of five free data file downloads per month has been increased to eight. This small increase allows our free users to get that little bit more from our open data service. As part of this change, a banner has been placed at the top of each dataset page to make the download limit clear. Happy downloading!

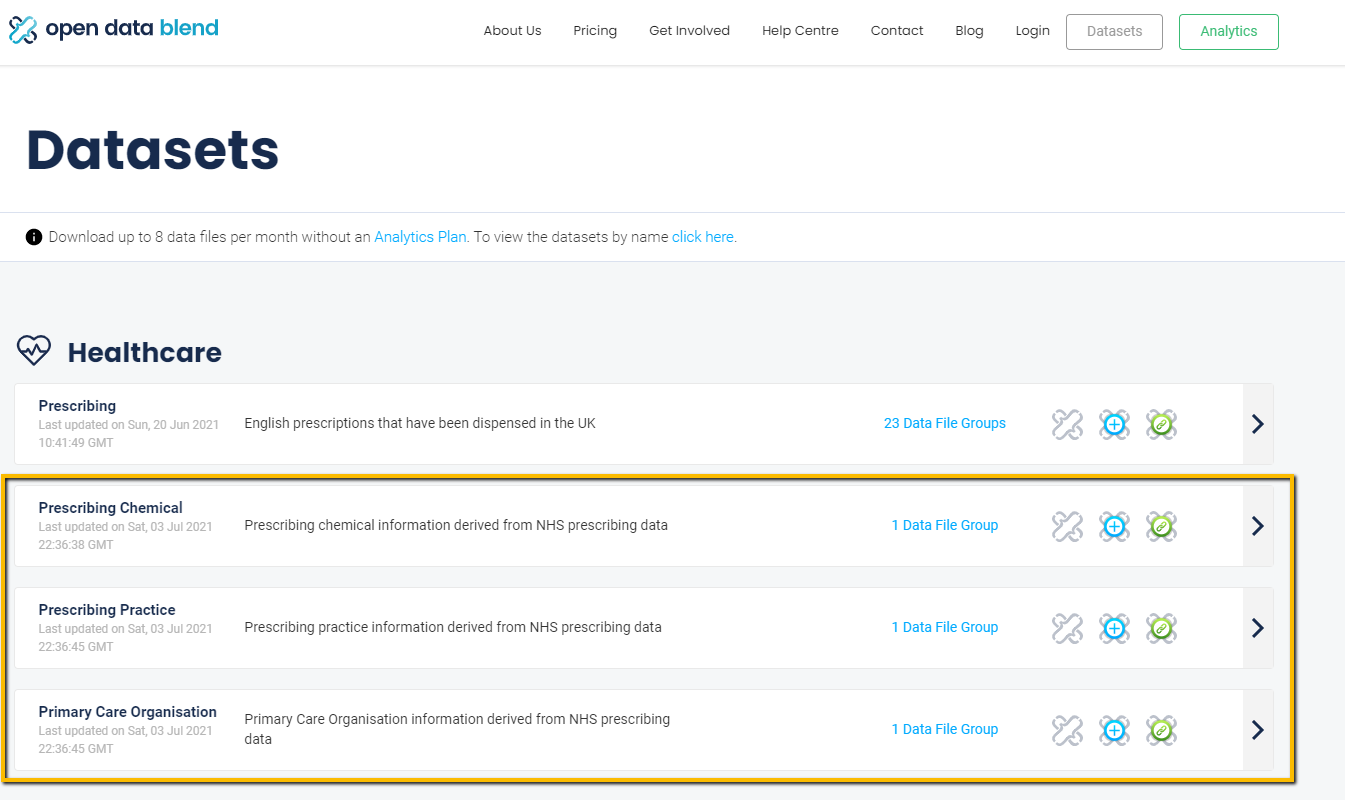
Discoverability Improvements
A set of popular data files have been added as stand-alone datasets to make them more discoverable:
The data files were previously available as part of larger collections of data files in our existing datasets (i.e. the Prescribing and Anonymised MOT datasets). Making these also available as standalone datasets means that they can more easily be found and used for data enrichment scenarios.
Open Data Blend for Python
The primary users of the Open Data Blend Datasets service are data engineers and data scientists. As part of our aim to make large and complex open data easier to use, we have developed a lightweight, easy-to-use extract and load (EL) tool that streamlines the task of getting data from the Open Data Blend Dataset API.
Install the PyPI package:
pip install opendatablend
Cache data files locally with just a few lines of code:
import opendatablend as odb
import pandas as pd
dataset_path = 'https://packages.opendatablend.io/v1/open-data-blend-road-safety/datapackage.json'
# Specify the resource name of the data file. In this example, the 'date' data file will be requested in .parquet format.
resource_name = 'date-parquet'
# Get the data and store the output object
output = odb.get_data(dataset_path, resource_name)
Load and analyse the cached data files in tools like Pandas:
# Read a subset of the columns into a dataframe
df_date = pd.read_parquet(output.data_file_name, columns=['drv_date_key', 'drv_date', 'drv_month_name', 'drv_month_number', 'drv_quarter_name', 'drv_quarter_number', 'drv_year'])
# Check the contents of the dataframe
df_date
Note: As the files are cached locally, you can use any tools to load and work with the data, not just Python.
Head over to the official GitHub repository to learn more, and don't forget to star it if you find it useful.
Follow Us and Stay Up to Date
Follow us on X and LinkedIn to keep up to date with Open Data Blend, open data, and open-source data analytics technology news. Be among the first to know when there's something new.
Blog hero image by Florian Steciuk on Unsplash.




