
Open Data Blend March 2022 Update


25th April 2022
By Open Data Blend Team
The Open Data Blend March 2022 update includes a new cloud storage integration through the Open Data Blend for Python library, the introduction of consulting services, and the launch of an affiliate programme.
Open Data Blend Datasets
English Prescribing Data for February 2022 Is Available
We have updated the Prescribing dataset with the latest available NHS English Prescribing Data which includes activity up until February 2022. You can download the data from the Open Data Blend Datasets Prescribing page, analyse it directly in supported BI tools through the Open Data Blend Analytics service, or instantly explore insights through the Open Data Blend Insights service.
Google Cloud Storage Support in Open Data Blend for Python
Last month, we extended Open Data Blend for Python to support Azure Blob Storage, Azure Data Lake Storage (ADLS) Gen2, and Amazon S3 as target file systems. This month, we have added support for Google Cloud Storage.
With a few simple lines of code, you can quickly ingest our datasets into your data lake in Google Cloud. Once ingested, you can interactively query and analyse the ORC and Parquet files using data lake analytics services like Google BigQuery and Databricks.
Here is an example of how easy it is to copy our datasets to Google Cloud Storage using Open Data Blend for Python:
import opendatablend as odb
dataset_path = 'https://packages.opendatablend.io/v1/open-data-blend-road-safety/datapackage.json'
access_key = '<ACCESS_KEY>' # The access key can be set to an empty string if you are making a public API request
# Specify the resource name of the data file. In this example, the 'date' data file will be requested in .parquet format.
resource_name = 'date-parquet'
# Get the data and store the output object using the Google Cloud Storage file system
configuration = {
"service_account_private_key_file" : "<PATH_TO_SERVICE_ACCOUNT_PRIVATE_KEY_FILE>",
"bucket_name" : "<BUCKET_NAME>", # e.g. odbp-integration
"bucket_location" : "<BUCKET_LOCATION>" # e.g. europe-west2
}
output = odb.get_data(dataset_path, resource_name, access_key=access_key, file_system="google_cloud_storage", configuration=configuration)
# Print the file locations
print(output.data_file_name)
print(output.metadata_file_name)
Want to learn more about how Open Data Blend for Python can help you to integrate our datasets? Head over to the GitHub or PyPI page.
Introducing Open Data Blend Consulting
We know that even with access to data that has been optimised for analytics, there is still quite a bit of work needed to make the most out of it. That is why we have introduced Open Data Blend Consulting, a set of analytics consulting services to accelerate the journey from dataset acquisition to business value.
Open Data Blend Consulting focuses on four technology areas that can be used to transform Open Data Blend datasets into a competitive edge for businesses: Data Engineering, SQL Lakehouse, Business Intelligence Insights, and Advanced Analytics.
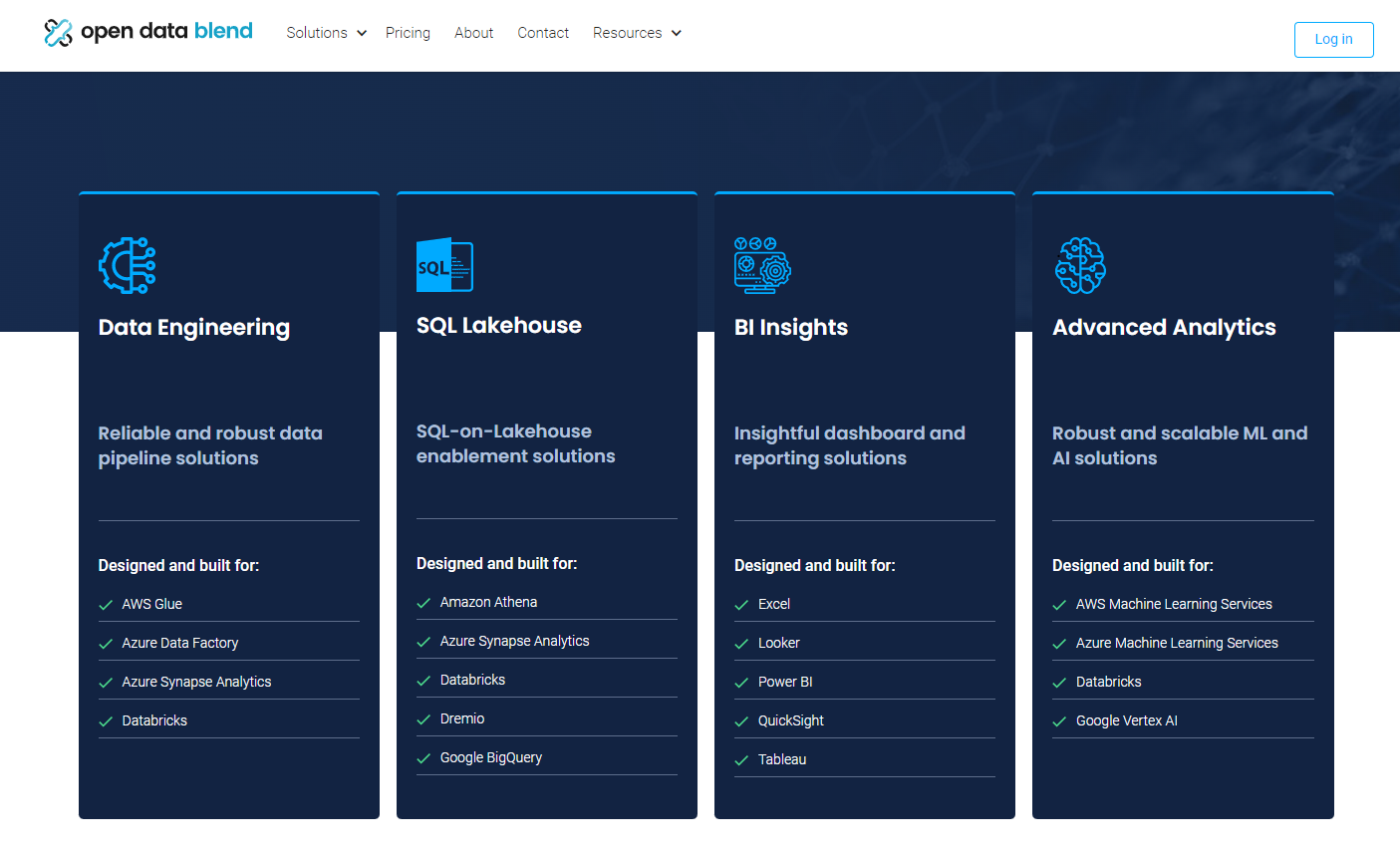
You can learn more about Open Data Blend Consulting here.
Introducing the Open Data Blend Affiliate Programme
We have launched the Open Data Blend Affiliate Programme which rewards individuals or companies with up to 20% recurring revenue on the Open Data Blend sales that they generate.
You can learn more about the Open Data Blend Affiliate Programme here.
Follow Us and Stay Up to Date
Follow us on X and LinkedIn to keep up to date with Open Data Blend, open data, and open-source data analytics technology news. Be among the first to know when there's something new.
Blog hero image by Caleb George on Unsplash.




